
Building shareyourpaper.org to make self-archiving the simplest way to increase a paper’s impact.

Introducing shareyourpaper.org, the simplest way for authors to legally self-archive and for your library to fill your repository.
Self-archiving needs to be simpler to unleash its power as an equitable route to open access. Yet, it’s too hard for individual repositories to overhaul their existing user experience. We’re building shareyourpaper.org to transform deposit from an often complicated, time-consuming process into one that’s possible in just a few clicks, for any repository without the need for complex integrations. Shareyourpaper.org is a tool that automates the deposit workflow — metadata entry, permissions and version checking — to require only the single manual step of uploading the paper itself. Libraries looking to fill their repositories can learn more and help us build the tool by signing up.
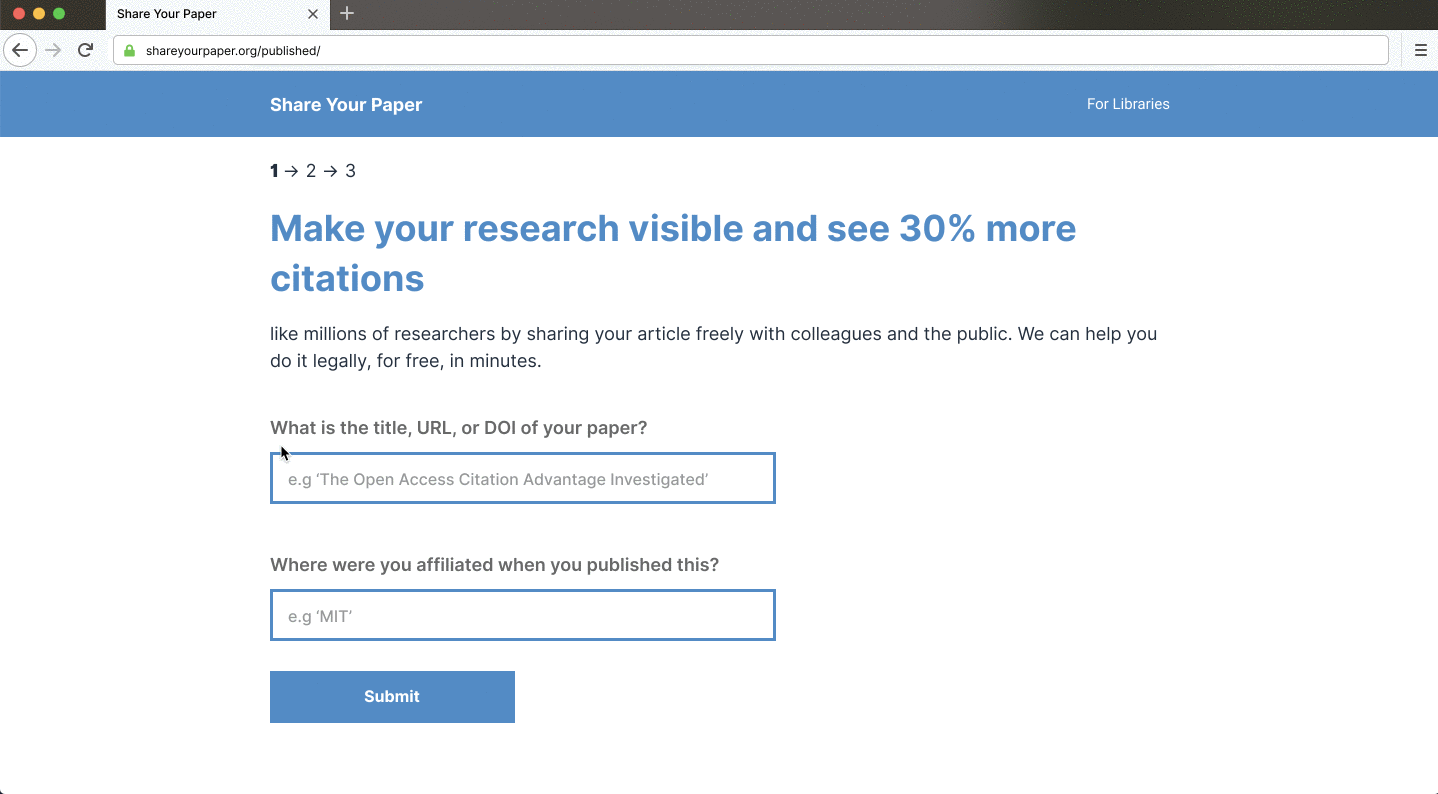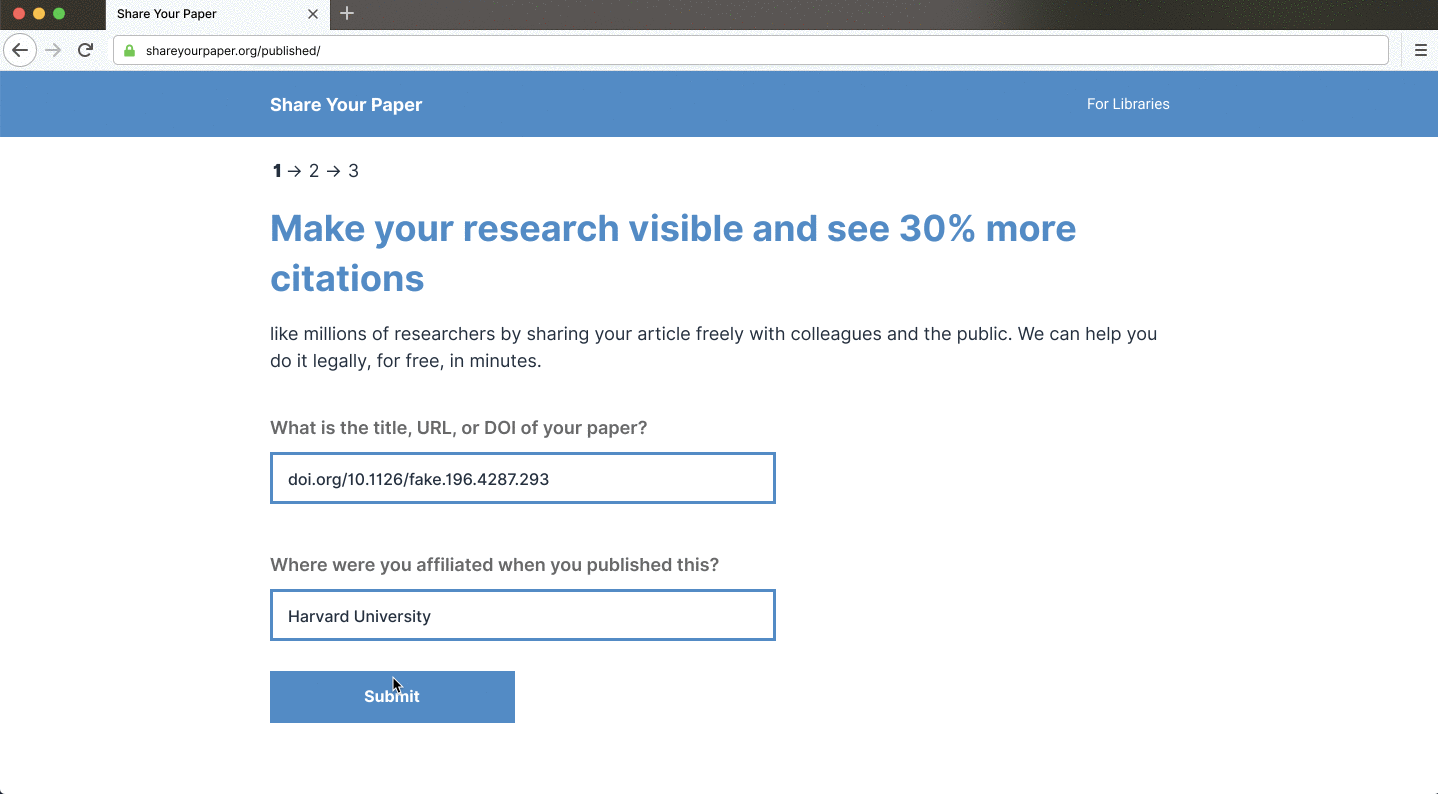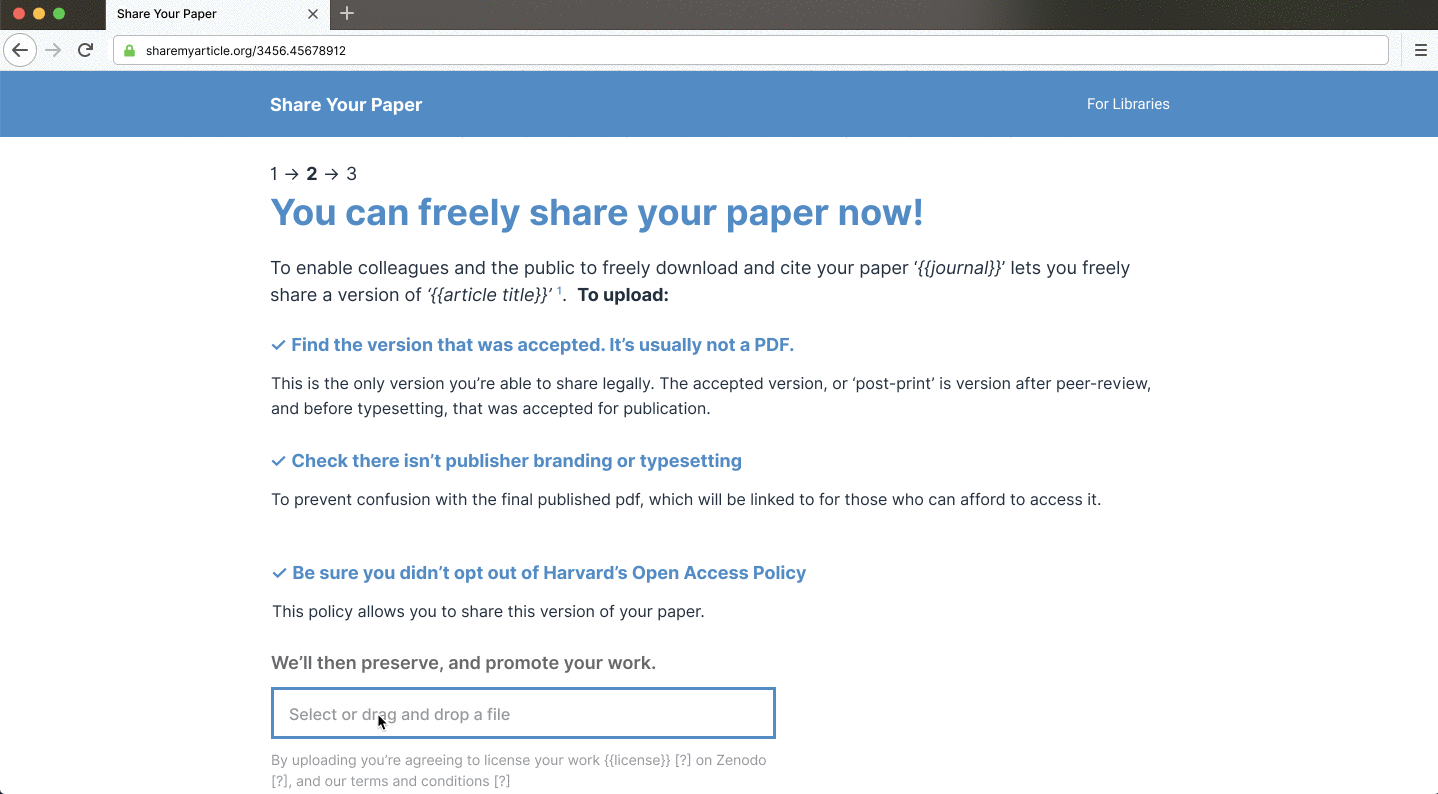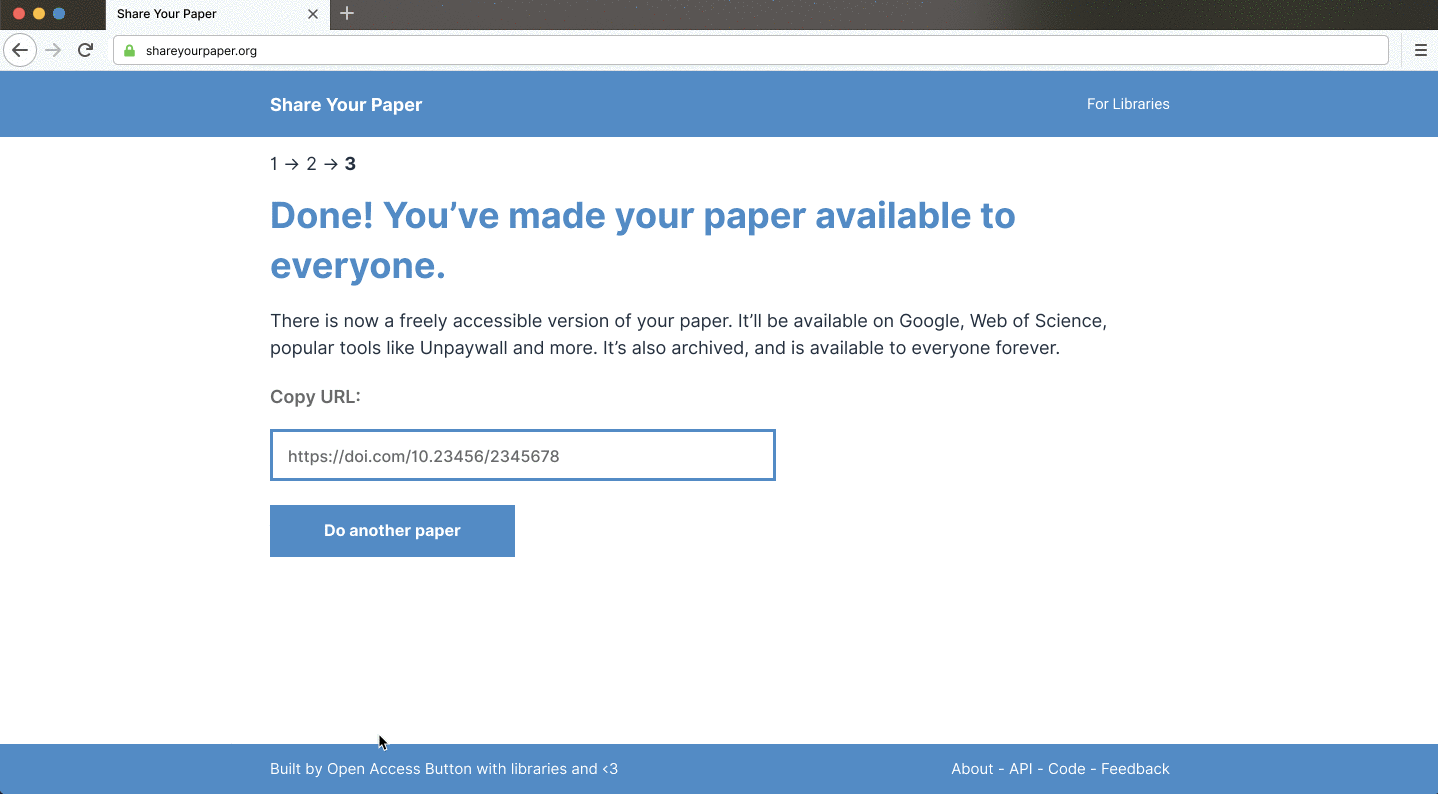
Shareyourpaper.org will allow libraries to significantly improve the deposit workflow and enable author-driven self-archiving without technical expertise or repository migration. This new tool will provide an institutional deposit portal, with direct deposit links for your repository and notifications of deposit. Instead of requiring complex repository integrations, shareyourpaper.org will deposit papers into Zenodo (an open-source repository operated by CERN) then support libraries pulling articles into their existing repository through bulk ingest and other mechanisms.
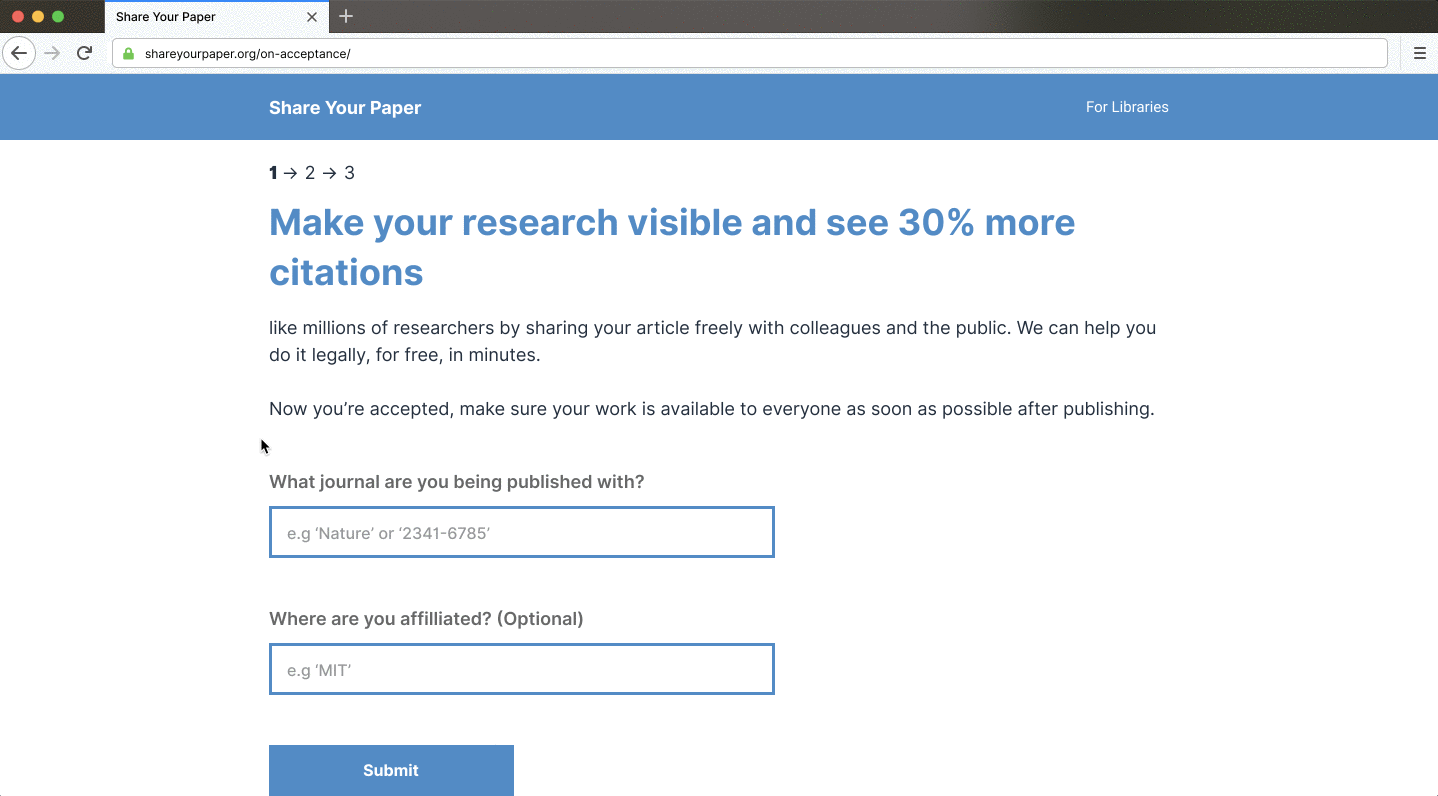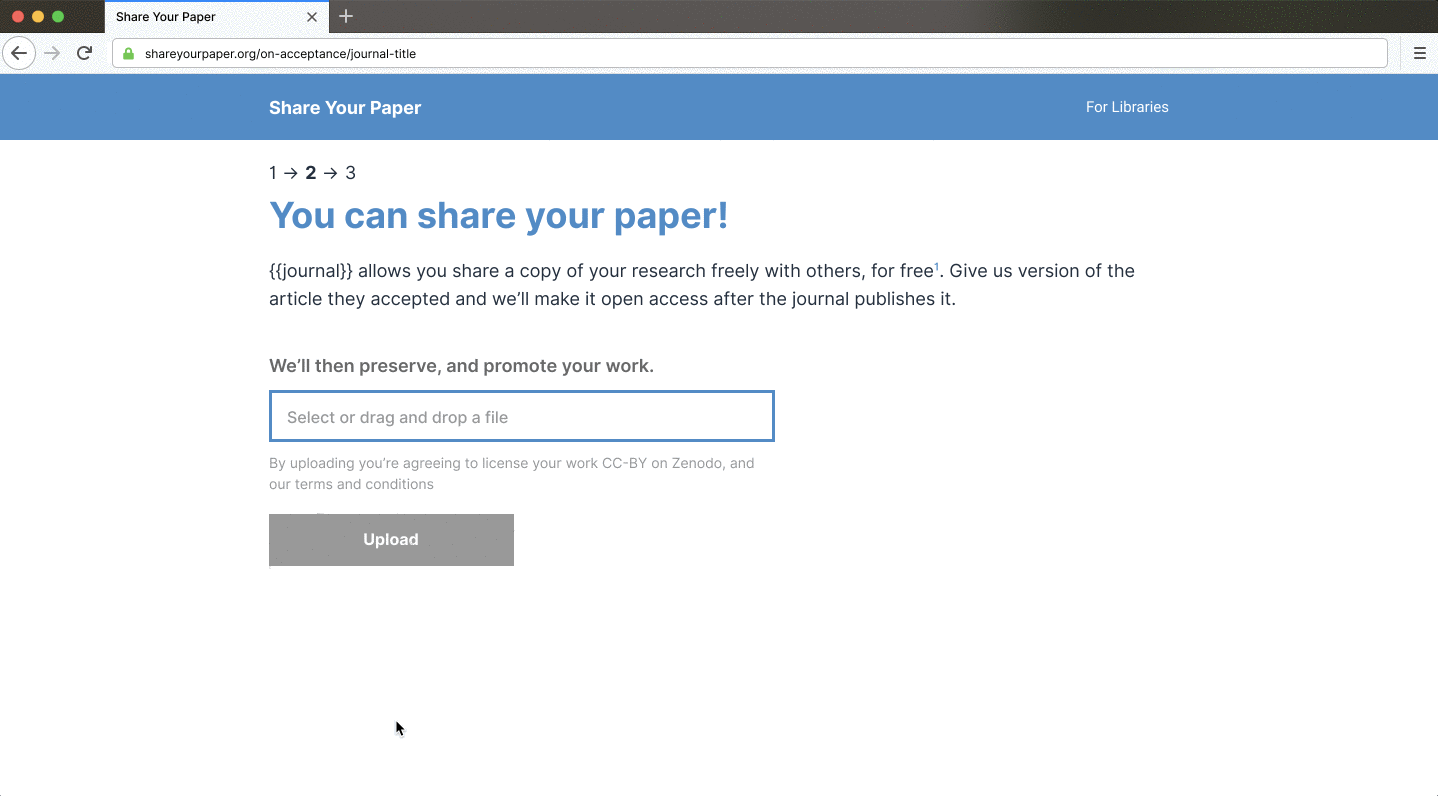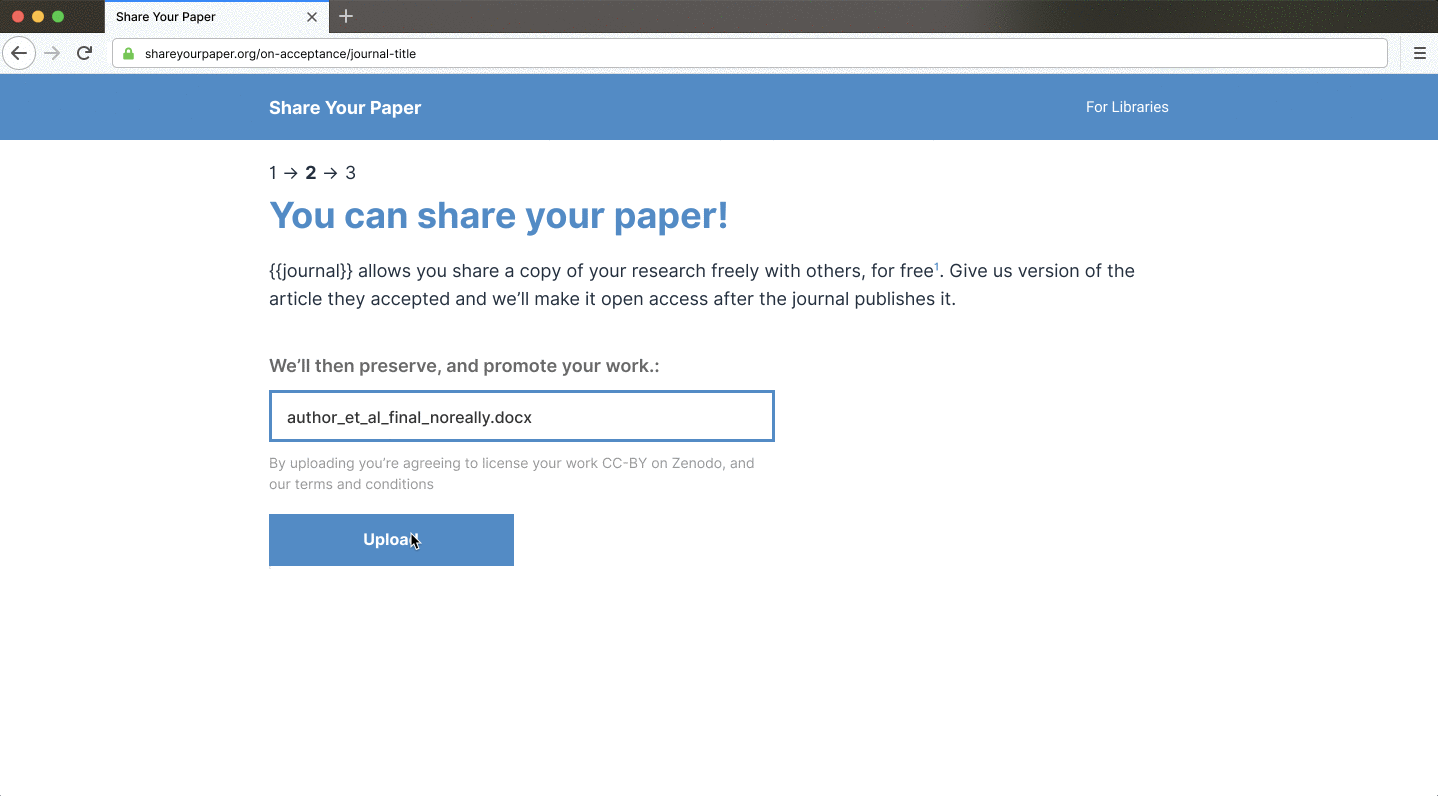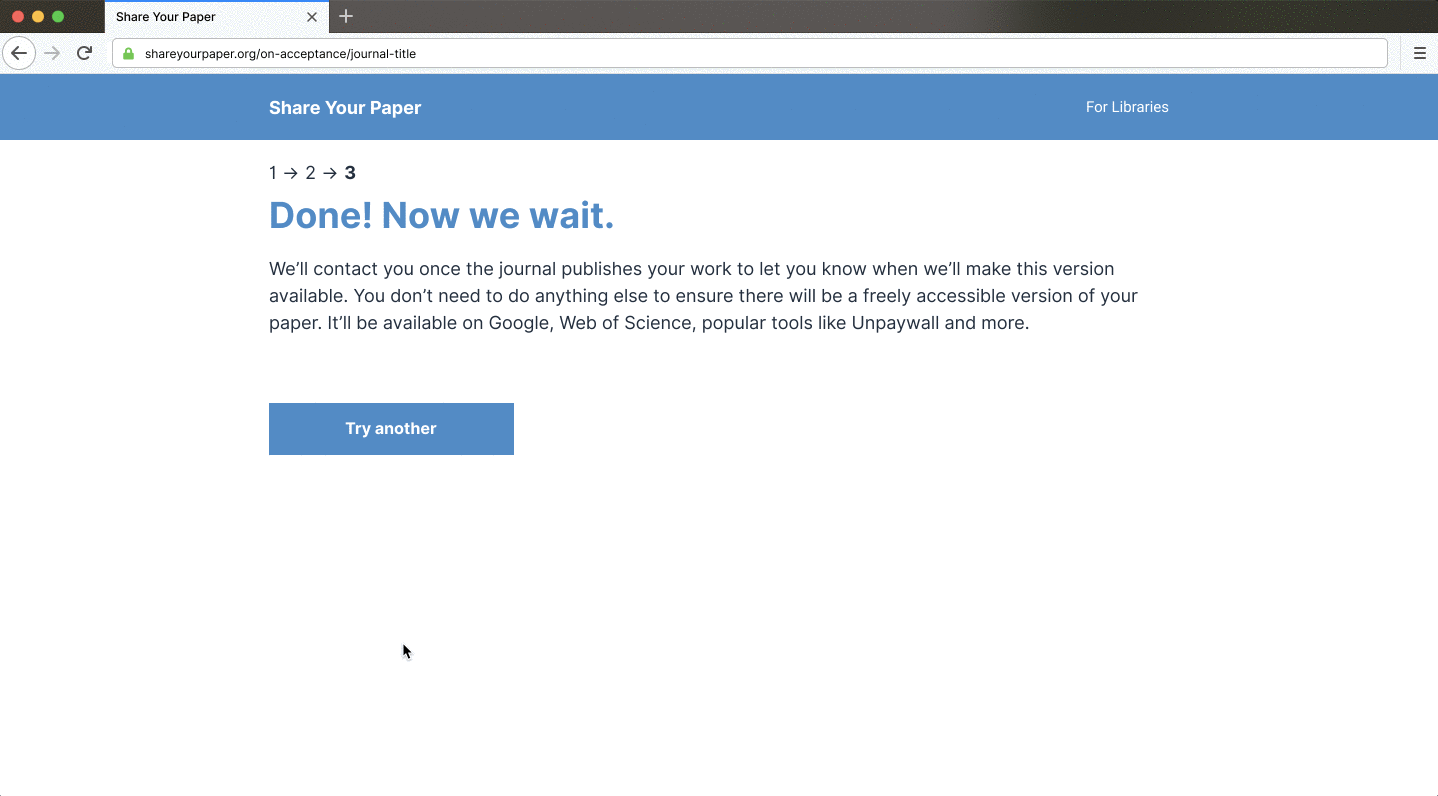
Shareyourpaper.org is being built to be intuitive to use. For example, if you know the DOI of the paper you want deposited, you can go directly to a simple deposit page for that paper. Adding the DOI to the end of the shareyourpaper.org URL will take you straight there. It’s a small feature with a big impact. For example, in a mail merge, you can send authors directly to a deposit page for their paper with the metadata automatically populated, saying clearly what version they can share and how to find it. All authors need to do is drag and drop their manuscript to deposit — no login necessary. When they do, we instantly and automatically check what they uploaded and provide further assistance if they get it wrong.

By making deposit simple and enabling others to do the same, we believe shareyourpaper.org can transform self-archiving, in process and perception, to make dramatically more content open access in an equitable way.
We’re looking to the library community for support in building and sustaining our work. Libraries that share our aims and are in a position to financially contribute can get in touch today to discuss how. Soon after release, we’re planning a paid-for version, at a flexible cost for libraries big and small. We’re consulting on the details, but we expect to offer the ability to deposit through our system without leaving your site. Setup would only require copying and pasting one line of code. In the paid version, you will also get upgraded versions of other tools, including InstantILL, alongside priority support, input, recognition, and more.
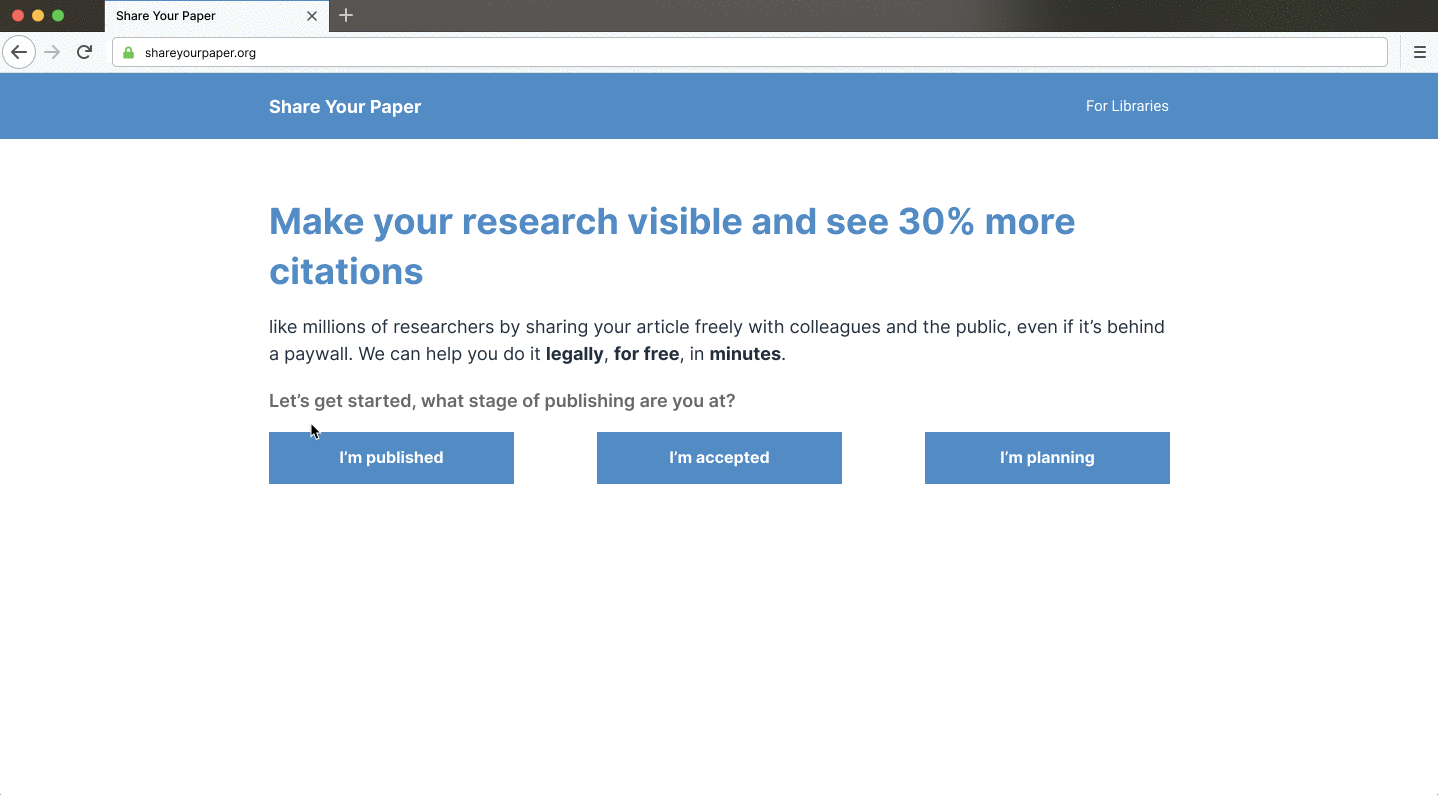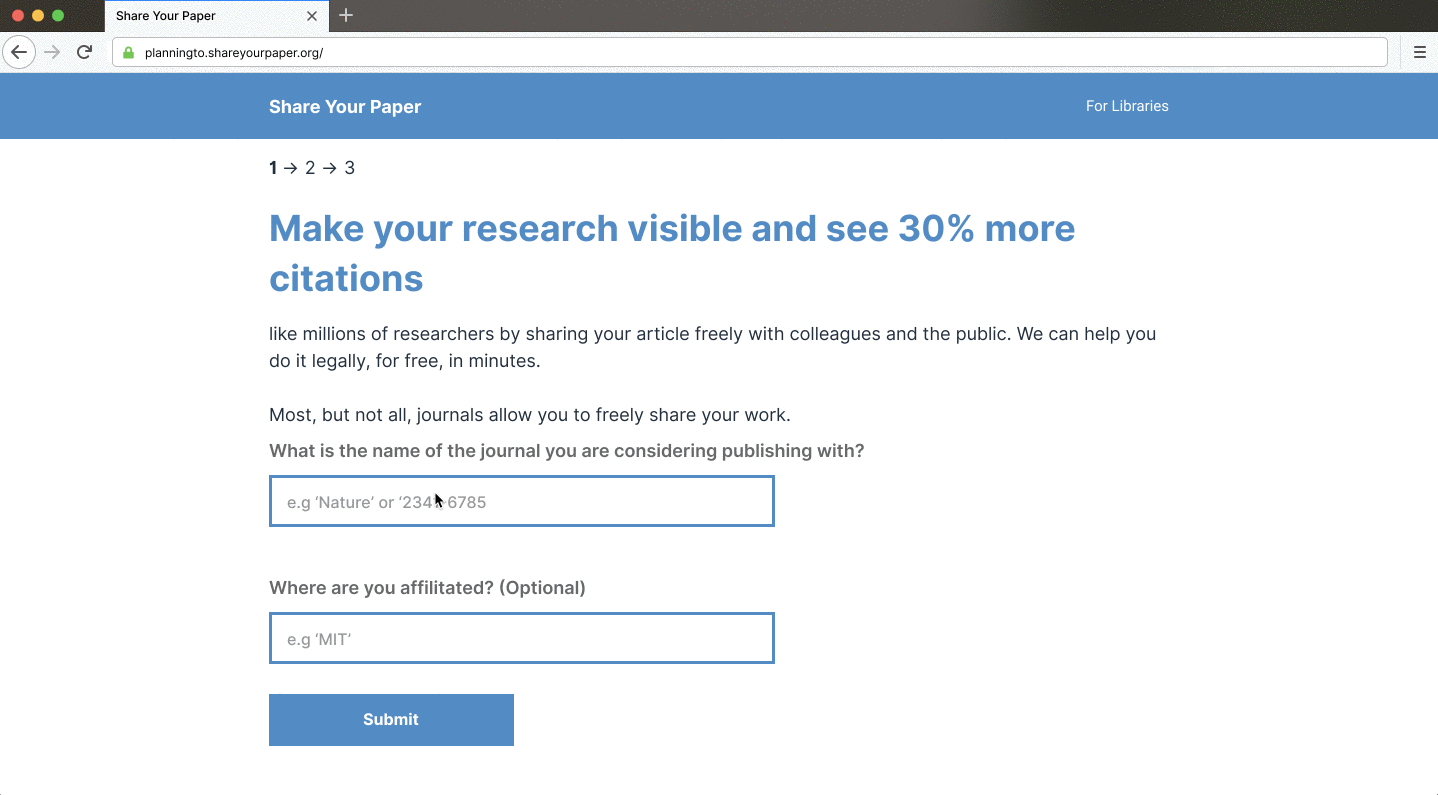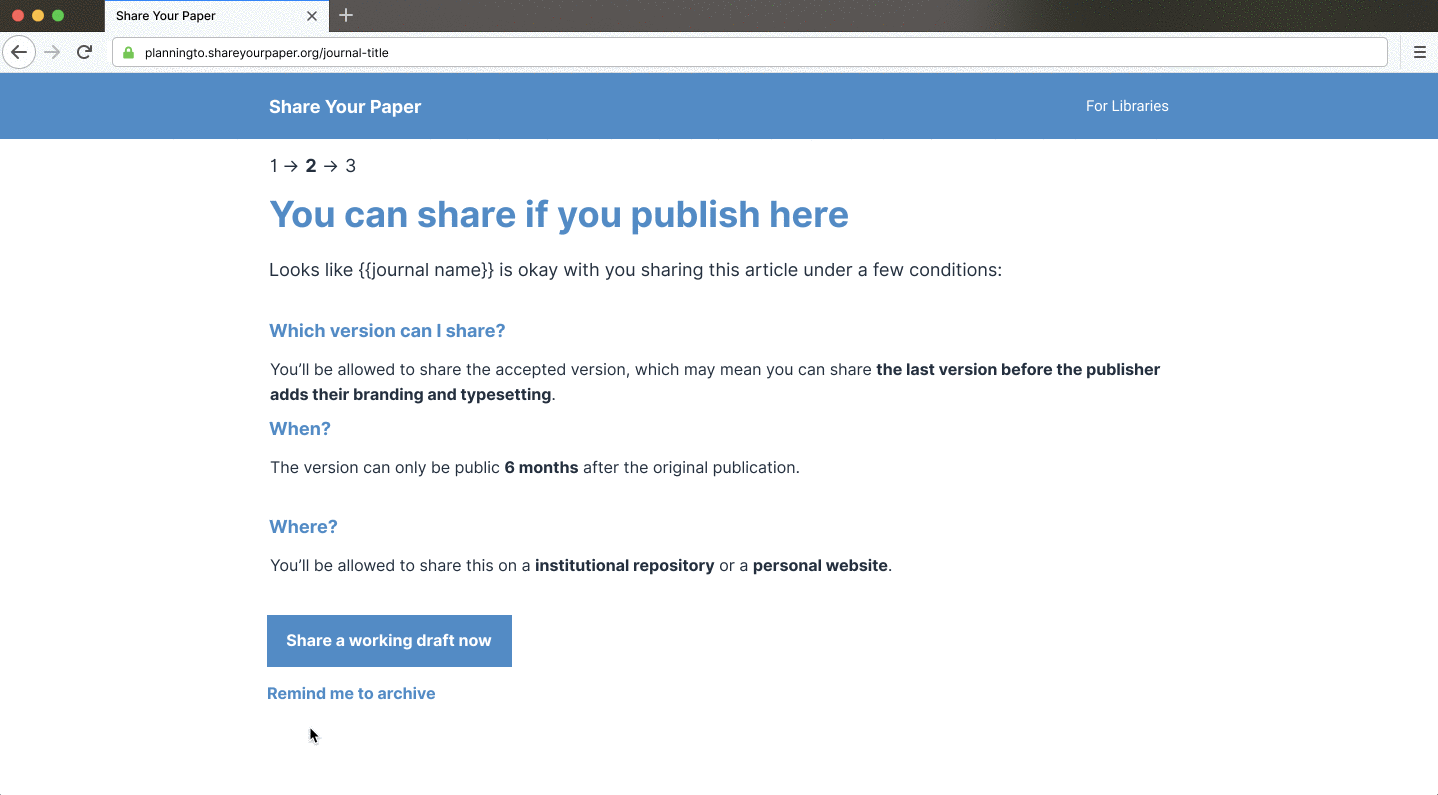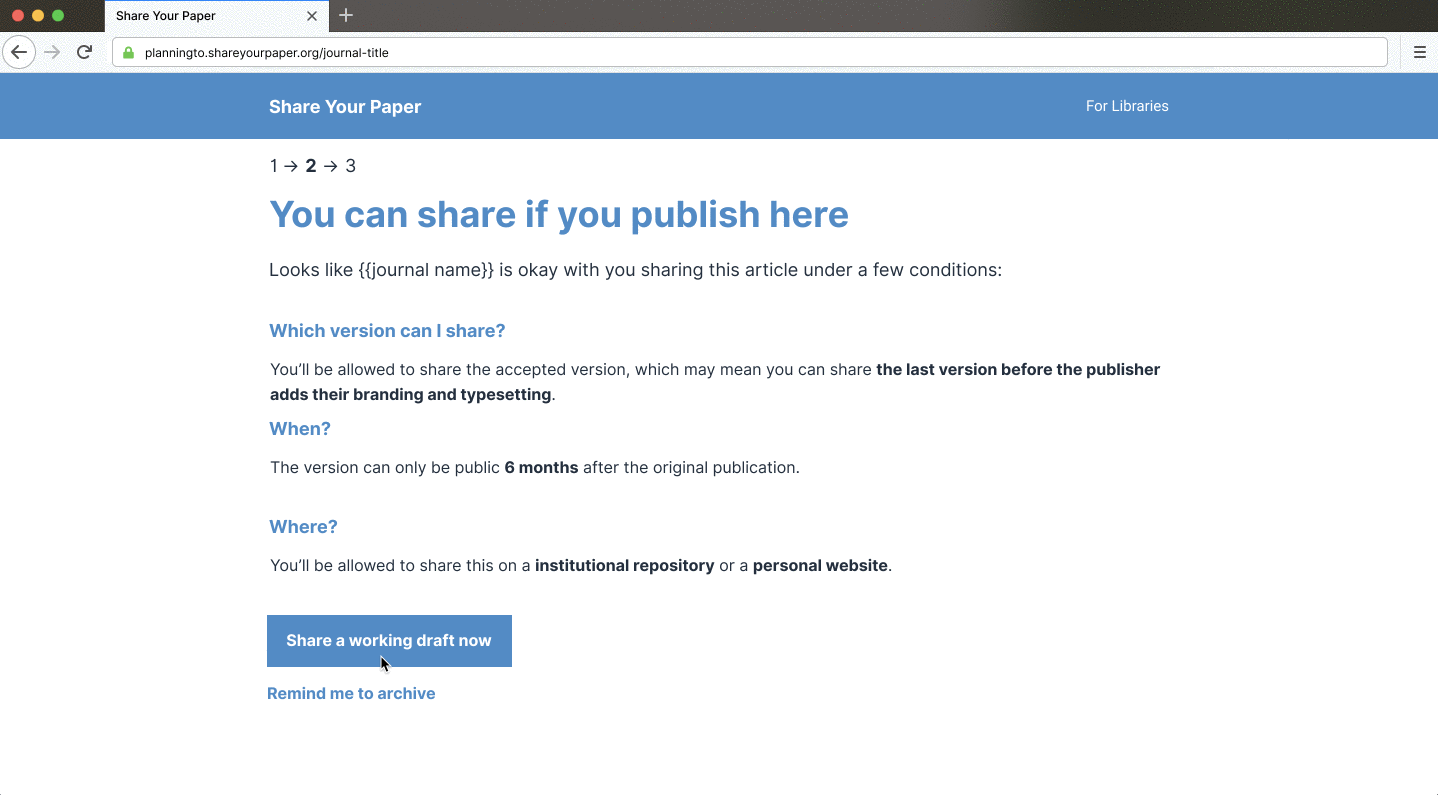
Shareyourpaper.org builds upon the insights gained asking thousands of authors to self-archive with our Request System, and novel tools we’ve built with the library community.

Late this year, we plan to launch shareyourpaper.org for anyone, everywhere, to deposit wherever they are in the publishing process. It’ll be free, built on open-source code, community-curated open data, simple documented APIs, library values, and resources that enable others to do even better. If you’d like to learn more or contribute in any way, please express your interest.
Thanks to the Arcadia Fund, which generously supported our work. We’re also grateful to many librarians, especially Leila Sterman, and those who’ve contributed to our other resources, for gifting their expertise. We’re still designing the tool, so if you have any questions or feedback, please email Joe@openaccessbutton.org.
