
New tool and dataset make permissions checking easier, faster, and clearer for libraries.

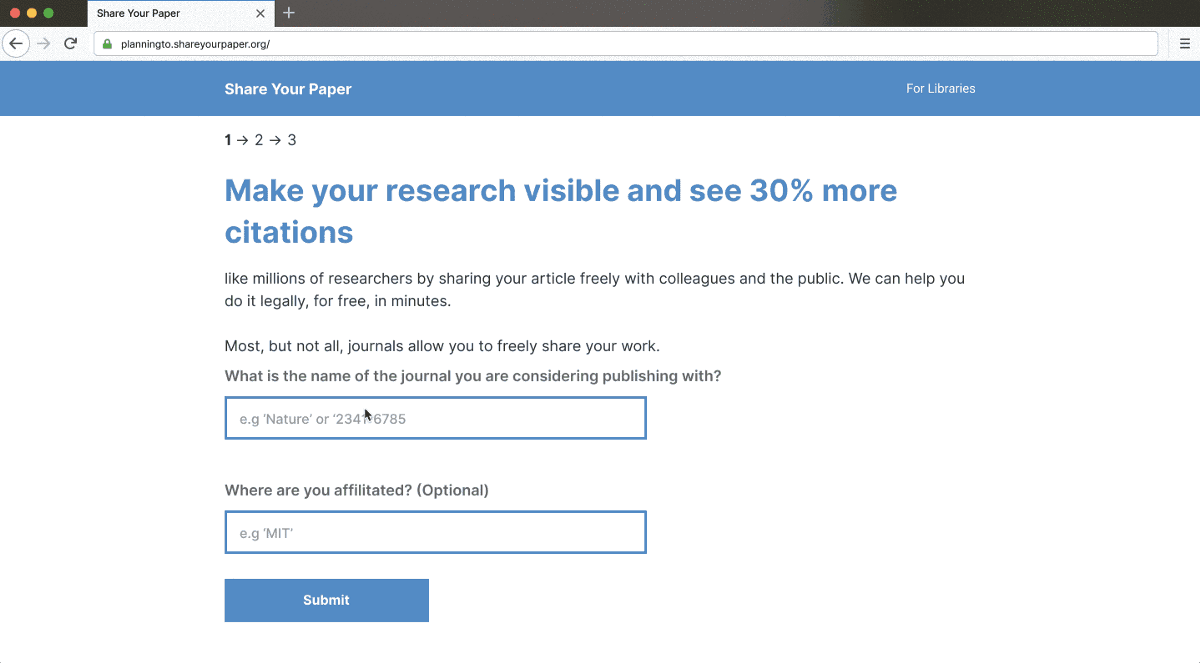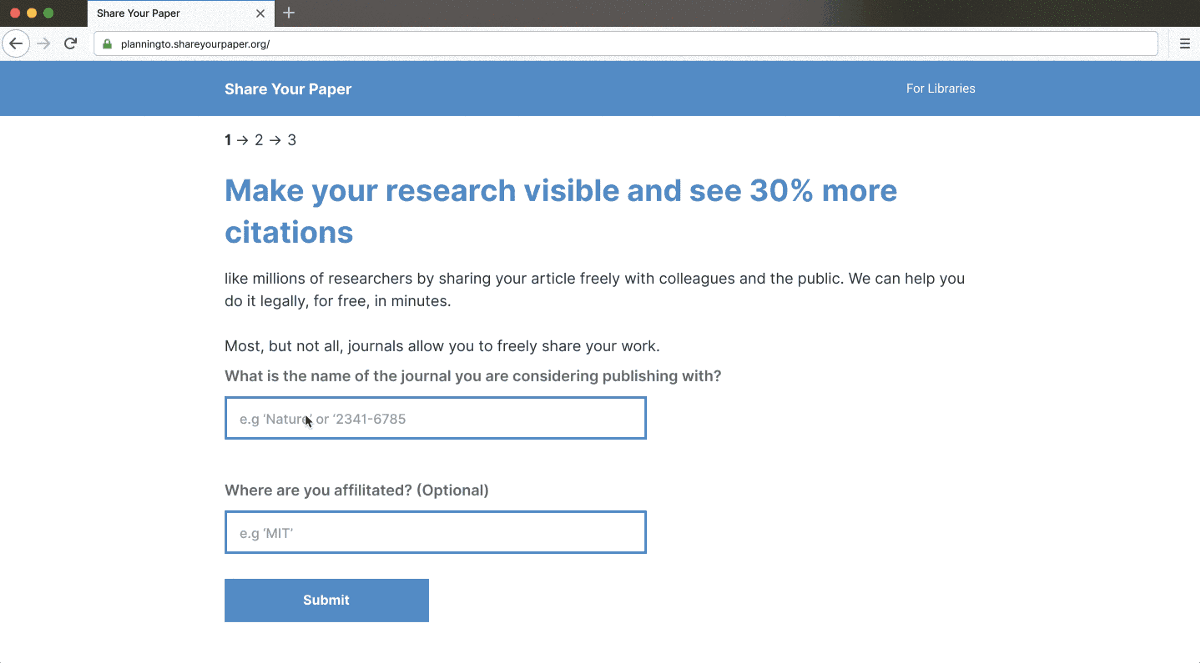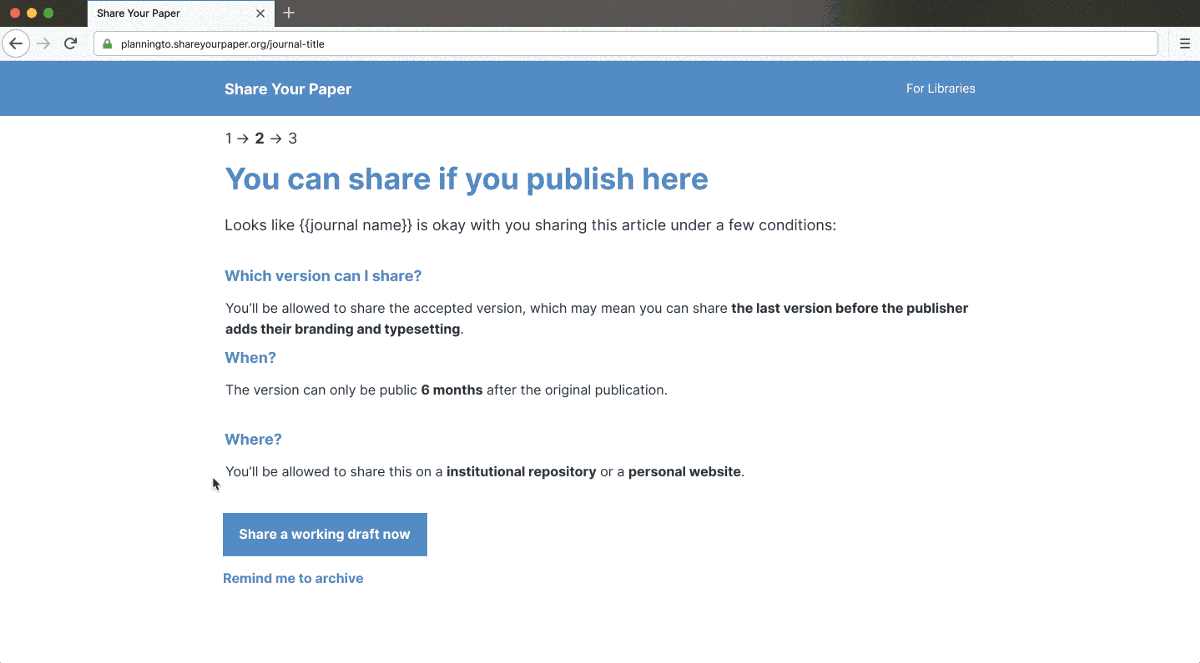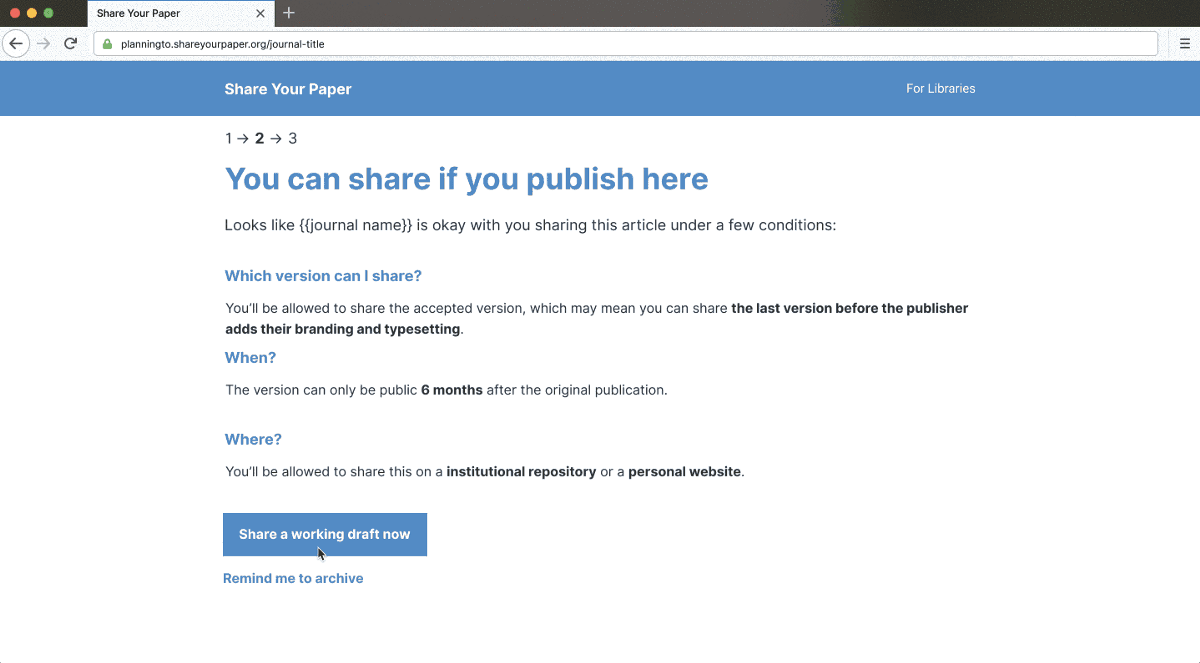
Together with librarians, we’re building a new way to perform permissions checking that is backed by a modern approach and informed by a decade of experience and open, community-editable, machine-readable data. Today, we’re releasing a prototype of that system, a bulk automated permissions checker (and its data), which is specialized for use during mediated deposit and en masse outreach and built to check hundreds of articles and journals in seconds. It returns comprehensive permissions information, along with complete article metadata and links to open access versions. Try the tool today at: openaccessbutton.org/permissions.
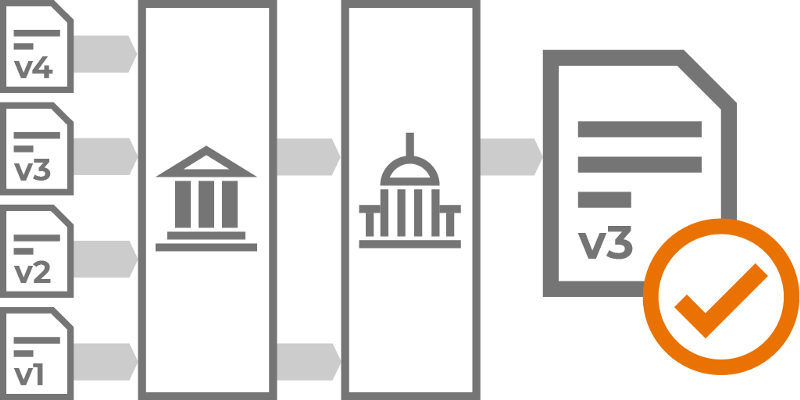
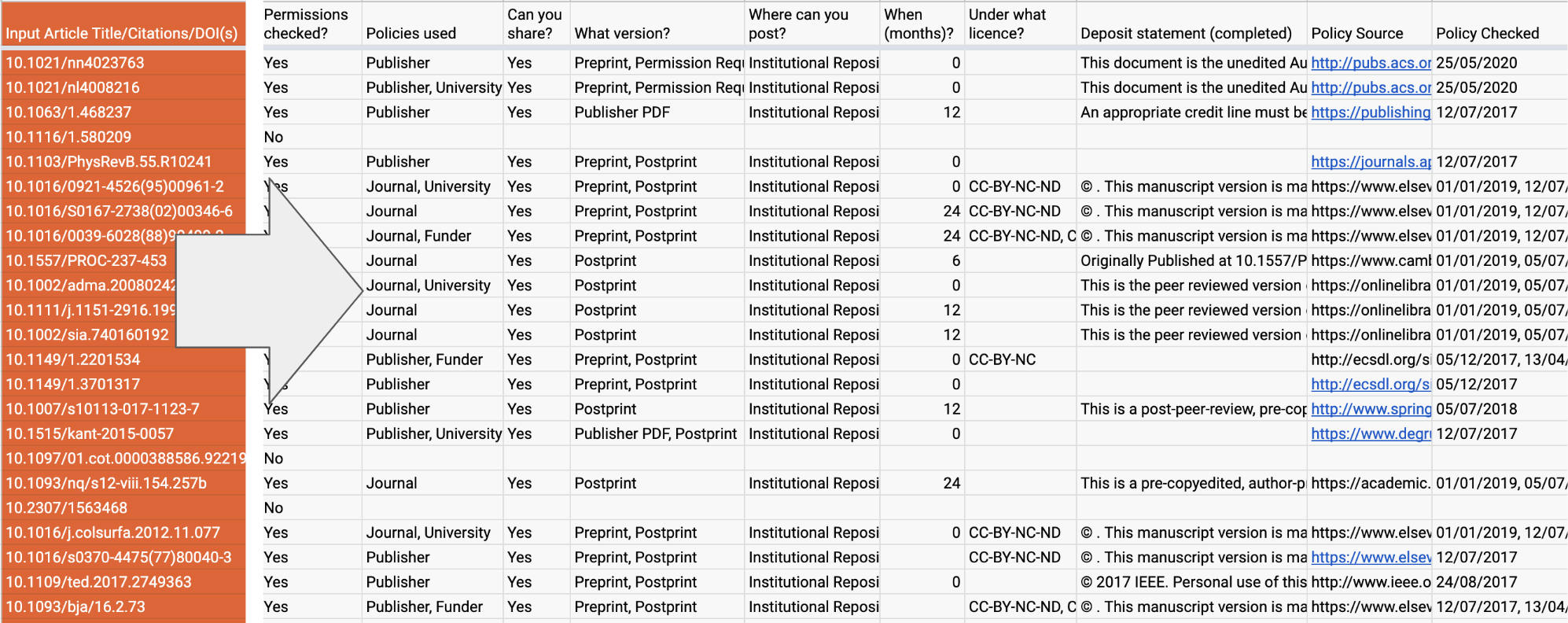
To use the bulk automated permissions checker, copy and paste in titles, DOIs, or ISSNs. We’ll then return critical permissions information, such as which version can be shared, embargo lengths, completed deposit statements, and under what license the work can be deposited, all in a clear and consistent format with sources to back it up. We take into account not just journal and publisher policies but also institution and funder policies. To put the permissions in context and provide information for deposit, the checker also provides article metadata and indicates if it’s already open access. Finally, we provide next actions for student workers or summaries for authors, or information can be exported to the next step of the workflow.
We were thrilled to work closely with Kenny Whitebloom and Sarah Wipperman at the University of Pennsylvania Libraries. “Mediated deposit is a great way to increase faculty participation in an institutional repository and to ensure that content is uploaded correctly, but it is a strain on a library in terms of time, expertise, staffing, etc.,” they said. “This new tool reduces many of these barriers to participation in permissions checking by making the process easier, faster, and more comprehensive. At the University of Pennsylvania, we have been working on refining our mediated deposit and permissions workflows for years and are excited to incorporate this more automated, streamlined, and integrated tool into our processes!”
To create this, we had to rethink and rebuild from the ground up, try something new, and utilizing our work with our Request System and the invaluable experience of the library community. There are two important parts. First, a database that details permissions given by 20,000 journals, 250 publishers, 80 universities, several funders and governments. We detail what permissions are granted by policies (structured for use by machines and people), when to apply them, and their source. Second, the permissions checking system then understands, gathers critical contextual information, and applies these on a per-article or journal basis, taking into account author affiliation, publication date, publication venue, contractual agreements, and more. Details can be found in the schema and documentation. Permissions checking is complex, and getting it right matters. We’re keen to get feedback from the community on whether the answers given are correct and what we’re not able to manage. Separately, we also provide results from existing sources such as SHERPA/RoMEO.
We’re looking to the expertise of librarians for support to maintain the database but hope to make that easy. If a policy is missing, needs updating, or review, you can instantly and quickly contribute and see it reflected. If you’ve previously kept your own details of policies, we’ll help you add them. To keep the quality of the data high, we’ll review new contributors, new policies, archive sources, automatically monitor policies for updates, and we’ve documented how to contribute. We’ve seeded the database with curated data from the University of Pennsylvania’s Publisher Policy Database, and the Harvard Open Access Project.
As we advance our effort to build dramatically simpler tools for authors to self-archive and more (cost-)effective workflows for libraries we’ll build APIs, making it more robust, and including more data on author affiliation and funding. This joins our family of tools for libraries, including templates for emailing authors, article version explainers, instructions on how to find author-accepted manuscripts, and a workflow that ties all these together. Libraries who’d like to be a leader in supporting that effort should get in touch.
Thank you to…
- Kenny Whitebloom and Sarah Wipperman at the University of Pennsylvania Libraries, whose work on the University of Pennsylvania’s Publisher Policy Database and structured permissions workflow served as essential sources and templates for this work. Their constant review and consultation were also essential.
- Peter Suber, who provided substantial review, also generously gave his time to talk us through properly utilizing universities policies, and his careful documentation of them enabled their inclusion.
- Leila Sterman, Matt Ruen, Alicia Huber, Devin Soper, Ryan Otto, Kathryn Pope, Sherry Lake, Rachel Smart, and Antonin Delpeuch, who provided substantial review and ideas at an early stage.
- Ian Harmon, April Gilbert, and Katherine Howard, who provided review of at an early stage.
- Natalia Norori, who manages the Open Access Button Request System, and alumni of the team, notably Chealsye Bowley and Sarah Melton, who taught us how to perform permissions checking.
- The work of SHERPA/RoMEO and ROARMAP, who continue to contribute immensely to this area.
We once again thank the Arcadia Fund, which has funded this effort and all the above tools.
What is permissions checking? It’s understanding what version of your work you can deposit, where, how, and when. Depending on when you published, with which publisher, which journal, and at which institution in which country, the answer can be quite different. Figuring this out is known as permissions checking, and it’s one of the biggest hurdles when self-archiving. While we don’t talk about it much as a community, getting it right and making it easy stands between us and a transformation in how self-archiving is done. For authors and librarians alike (and the tools they use), permissions checking is a complex and slow task, and there isn’t enough tooling to help digest the myriad policies into clear answers.
Go back to the blog.
